
近年来,大模型技术竞争日趋白热化,OpenAI 的 GPT 系列和 Google 的 Gemini 等模型不断刷新行业标准。
近日,Kimi 团队发布了最新的多模态推理大模型 Kimi k1.5,性能追平 OpenAI 的 o1 模型正式版,并在多个推理任务上表现出色。更令人振奋的是,Kimi 团队首次公开了技术报告,详细介绍了模型的训练细节和核心技术。
毕业于斯坦福大学的英伟达知名科学家 Jim Fan 在海外社交平台对该模型不吝赞美:
推文的结尾 Jim 称赞本报告令人振奋,即便是假期,也值得一读。
为了推动技术社区的进步,Kimi 团队将 k1.5 的技术细节和训练方法完全公开:
https://github.com/MoonshotAI/kimi-k1.5
摘要:语言模型通过下一个词预测进行预训练已被证明在计算扩展方面是有效的,但其受限于可用训练数据的数量。强化学习(RL)的扩展为人工智能的持续改进开辟了新的方向,核心在于大型语言模型(LLMs)能够通过学习探索并获取奖励来扩展其训练数据。
然而,之前发表的研究并未取得具有竞争力的成果。鉴于此,我们详细介绍了 Kimi k1.5 的训练细节与整体框架,包括其 RL 训练技术、多模态数据配方和基础设施优化。
长上下文扩展和改进的策略优化方法是该模型的关键,主要是建立一个简单而有效的 RL 框架,这个框架无需依赖更复杂的技术,如蒙特卡洛树搜索、价值函数和过程奖励模型。
值得一提的是,模型在多个基准测试和模态中实现了最先进的推理性能——例如,AIME 上 77.5 分,MATH 500 上 96.2 分,Codeforces 上 94 百分位,MathVista 上 74.9 分——与 OpenAI 的 o1 相当。
此外,我们提出了有效的从长链思维到短链思维的方法,利用长链推理(CoT)技术改进短链推理模型,从而获得 SOTA 的短链推理性能——例如,AIME 上 60.8 分,MATH500 上 94.6 分,LiveCodeBench 上 47.3 分——大幅超越现有的短链推理模型,包括 GPT-4o 和 Claude Sonnet 3.5(最高提升达+550%)。
Kimi k1.5 的服务即将在 kimi.ai 上线。
现在,让我们来盘点一下本次 Kimi k1.5 的核心思路与技术要点,一起揭开 Kimi k 的神秘面纱!

在学术数据集上,Kimi k1.5 的性能追平甚至超过了目前行业内顶尖的 OpenAI o1 满血版。具体来说,在 Long CoT 和 Short CoT 两项大类任务上,模型的性能表现分别是:
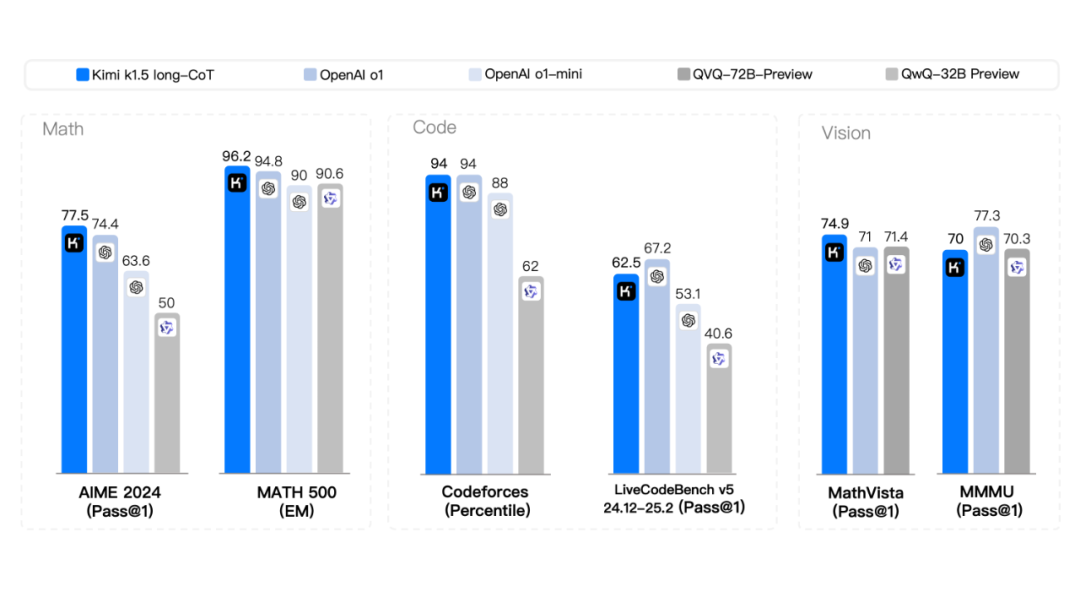
从数据中不难看出,Kimi k1.5 在多个任务上表现亮眼,尤其是在数学推理任务上,Kimi k1.5 的性能远超其他同类型竞品,展现了强大的推理能力。

细节全公开,核心还是在 RL
Kimi 团队成员在知乎平台详细分享了背后的思考过程:https://www.zhihu.com/question/10114790245/answer/84028353434
总结来说,提及的核心论点是:
激发模型自主搜索能力:让模型能够自行搜索,o1 没有限制模型如何思考,所以不要在思考的阶段引入 Structure,也就是不要引入结构化的先验知识,核心在于激发模型本身能力;
精确的 Reward 设计:不要被 Reward Model 给限制住了。核心在于提升 reward 模型。与常规的过程奖励模型(PRM)思路不同,需要鼓励模型自己搜索式思考,允许犯错;
结果为导向的 RL 训练:关于奖励模型,不管模型中间做错了什么,只要不是重复的,那么最后模型做对了,就认为这是一个好的探索,值得鼓励。反之,如果模型一顿探索,最后做错了,那么再努力也是错,要惩罚。
带着这些先验知识,我们就可以更容易理解报告里面所呈现的内容了。按照上面的结论来梳理,核心就是以最终结果作为 reward,做对加梯度,做错减梯度。接下来的核心问题就在于如何让模型的输出变长。
庆幸的是,模型会随着训练提升 performance 也不断增加 token 数。这种模型在 RL 训练过程中自己涌现的能力, 现在正好能满足让模型输出变长的需求。
除了核心思路,Kimi 团队在报告中还详细介绍了多项关键训练技巧,这些技巧在提升模型性能方面起到了至关重要的作用。具体来说,这些技巧包括:
策略优化(采用在线镜像下降算法)来提升模型的推理能力,鼓励探索多样化的推理路径,即使某些路径可能包含错误,只要最终能恢复并得到正确答案,模型仍能从中学到有价值的经验。为了应对模型在训练过程中生成的过长响应;
引入了长度惩罚机制,通过奖励较短的正确响应并惩罚过长的响应,提升 token 效率。采样策略方面,采用课程采样和优先级采样,逐步从简单任务过渡到复杂任务,并优先训练模型表现较差的问题,提升整体性能。
- 在训练基础设施上,系统采用大规模 RL 训练框架,结合部分 rollout 技术和混合部署策略,优化 GPU 资源使用,减少计算开销,并通过代码沙箱确保代码执行的安全性和可靠性。这些技术的结合使得 Kimi k1.5 在复杂推理任务中表现出色,同时保持高效的训练和推理效率。

推理越长,模型通常都会取得更好的效果,然而这也会带来计算成本与时间延迟的代价。Long2Short 技术的核心目标是将长链推理(Long-CoT)模型的推理能力迁移到短链推理(Short-CoT)模型中,从而实现在有限的 token 预算下提升模型整体性能。 - 模型合并(Model Merging):通过将长链模型和短链模型的权重进行简单的平均,生成一个新的模型,无需额外训练;
- 最短拒绝采样(Shortest Rejection Sampling):对同一个问题生成多个响应,选择所有正确响应中最短的那条进行监督微调;
- 直接偏好优化(DPO):利用长链模型生成多个响应样本,选择最短的正确解作为正样本,较长的响应(包括错误和正确的较长响应)作为负样本,用于 DPO 训练;
- Long2Short 强化学习(Long2Short RL):在标准 RL 训练后,选择一个在性能和 token 效率之间平衡的模型作为基础模型,进行单独的 Long2Short RL 训练,应用长度惩罚并显著减少最大 rollout 长度。
Long2Short 算法在 token 效率上表现最佳,相比其他方法(包括 DPO 和模型合并)具有更高的效率,能够在较少的 token 消耗下实现较高的性能。在学术数据集上,Long2Short 的效果是:
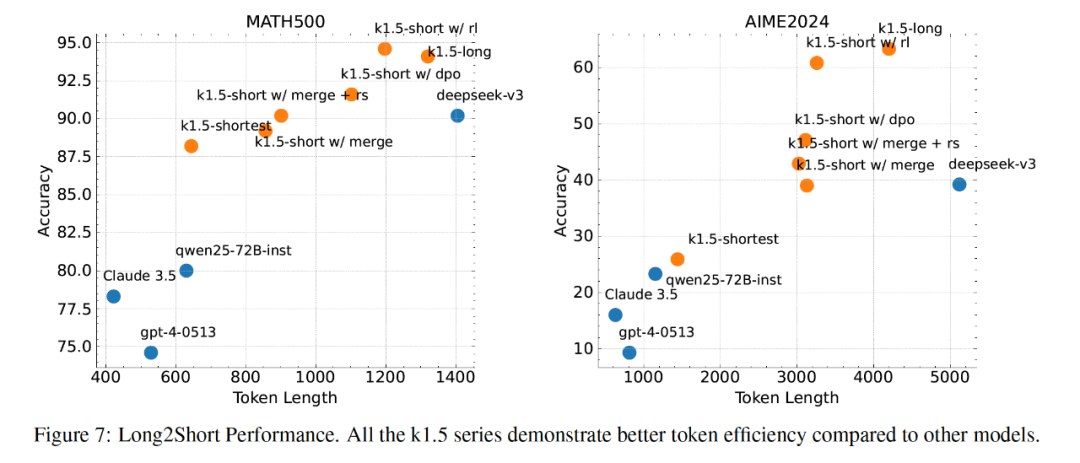
图中越靠近左上角模型性能最优,可以看出,在 short CoT 设定下,模型的性能基本和 long CoT 持平,token 减小效果显著。 Long2Short 技术在实际应用中具有广泛的价值。例如,在实时对话系统中,Long2Short 技术可以显著降低响应时间,提升用户体验;在代码生成任务中,短链推理可以在保证性能的同时减少计算资源消耗。通过 Long2Short 技术,Kimi k1.5 能够在有限的 token 预算下实现高性能推理,为用户提供更高效、更经济的 AI 服务。
写在最后:未来展望
2024 年 5 月和 9 月,OpenAI 先后发布了 GPT-4o 和 o1 两款模型,分别聚焦于多模态理解和强化学习两大技术方向。在这两个领域,国内 AI 企业也在积极布局,竞争日趋白热化。目前,Kimi 模型的表现与多模态的正式版 o1 最为接近,这引发了外界对该公司 2025 年发展的广泛关注与期待。据月之暗面透露,2025 年,Kimi 团队将继续推进 k 系列强化学习模型的迭代升级,进一步扩展多模态能力,覆盖更多应用场景,并全面提升模型的通用性和适应性。让我们一起期待下一代模型的到来!🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
▼ 点击「 阅读原文」,阅读完整报告



