这是两个名为DataQualityMetrics和ProcessingMetrics的数据类,它们是初始化数据类型的非常短的代码块。它们是不言自明的。@dataclass
classDataQualityMetrics:
"""Store data quality metrics"""
missing_data_pct: float
outlier_pct: float
stale_data_pct: float
gaps_detected: Dict
gap_count: int
gap_duration: timedelta
data_freshness: timedelta
quality_score: float
@dataclass
classProcessingMetrics:
"""Store processing metrics"""
processing_time: float
memory_usage: float
error_count: int
cache_hit_rate: float
feature_count: int
2.辅助类(Auxiliaries)
在系统初步运行若干次后,观测到存在性能瓶颈以及资源管理方面的问题,遂引入CacheManager类。
CacheManager类的功能为存储高频访问数据,以此降低数据库负载并减少延迟。该类分别针对原始数据与特征数据设置独立缓存,其缓存有效期分别设定为1小时和30分钟。同时,通过设定最大缓存大小限制,对内存使用进行有效管控。
在构建CacheManager和MonitoringServer类时,大量借助了Claude 3.5 Sonnet工具。尽管明确需要缓存模块与监控模块,但当前的实现方式在效率方面存在显著不足 。
class CacheManager:
"""Manages data and feature caching"""
def__init__(self, cache_size: int = 100):
self.data_cache = cachetools.TTLCache(
maxsize=cache_size,
ttl=3600# 1 hour TTL
)
self.feature_cache = cachetools.TTLCache(
maxsize=cache_size,
ttl=1800# 30 minutes TTL
)
self.logger = logging.getLogger('CacheManager')
self.hits = 0
self.misses = 0
defget_cache_key(self, symbol: str, start_time: datetime, end_time: datetime) -> str:
"""Generate cache key"""
returnf"{symbol}:{start_time.isoformat()}:{end_time.isoformat()}"
defget_from_cache(self, key: str, cache_type: str = 'data') -> Optional[pd.DataFrame]:
"""Retrieve data from cache"""
try:
cache = self.data_cache if cache_type == 'data'else self.feature_cache
if key in cache:
self.hits += 1
return cache[key]
self.misses += 1
returnNone
except Exception as e:
self.logger.error(f"Error retrieving from cache: {e}")
returnNone
defstore_in_cache(self, key: str, data: pd.DataFrame, cache_type: str = 'data'):
"""Store data in cache"""
try:
cache = self.data_cache if cache_type == 'data'else self.feature_cache
cache[key] = data
except Exception as e:
self.logger.error(f"Error storing in cache: {e}")
@property
defhit_rate(self) -> float:
"""Calculate cache hit rate"""
total = self.hits + self.misses
return self.hits / total if total > 0else 0.0
辅助部分的第二个组件是MonitoringServer类。此为可选类,目前尚未投入使用。它作为一个HTTP接口,具备捕获指标以及监测缓存性能的功能。该类对中频交易(MFT)系统的影响极小,仅使处理时间增加了0.14秒。鉴于不希望仅通过文本输出方式进行全面监控,后续有计划启用该类。
class MonitoringServer:
"""Handles monitoring endpoints and metrics collection"""
def__init__(self, host: str = 'localhost', starting_port: int = 8080):
self.host = host
self.starting_port = starting_port
self.port =
None
self.app = web.Application()
self.metrics = {}
self.logger = logging.getLogger('MonitoringServer')
asyncdeffind_free_port(self) -> int:
"""Find a free port starting from self.starting_port"""
port = self.starting_port
while port < self.starting_port + 100: # Try 100 ports
try:
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.bind((self.host, port))
sock.close()
return port
except OSError:
port += 1
raise OSError("Could not find a free port")
asyncdefstart(self):
"""Start monitoring server"""
self.app.router.add_get('/metrics', self.get_metrics)
self.app.router.add_get('/health', self.health_check)
runner = web.AppRunner(self.app)
await runner.setup()
site = web.TCPSite(runner, self.host, self.port)
await site.start()
self.logger.info(f"Monitoring server started at http://{self.host}:{self.port}")
asyncdefget_metrics(self, request: web.Request) -> web.Response:
"""Endpoint for getting current metrics"""
return web.json_response(self.metrics)
asyncdefhealth_check(self, request: web.Request) -> web.Response:
"""Basic health check endpoint"""
return web.Response(text='healthy')
defupdate_metrics(self, new_metrics: Dict):
"""Update current metrics"""
self.metrics.update(new_metrics)
3.主类(Main Classes)
本代码旨在解决核心问题,即处理数据与市场差距相关的难题。经过约10 - 12次迭代优化,最终取得了较为理想的结果,具体前后输出情况可在结果部分查看。
在该模块中,DataQualityChecker和DataMonitor这两个主类发挥着关键作用。DataQualityChecker主要负责验证市场数据的质量,会对市场交易时间段内的数据进行检查,排查数据差距、缺失值以及异常值等问题。该类会设定市场交易时间(美国东部时间上午9:30至下午4:00),并计算相应的质量指标和分数。
class DataQualityChecker:
"""Handles data quality validation"""
def__init__(self, max_missing_pct: float = 0.1,
max_outlier_std: float = 3.0,
max_stale_minutes: int = 5,
min_gap_minutes: float = 1.0
): # Changed to minutes and default to 1.0
self.max_missing_pct = max_missing_pct
self.max_outlier_std = max_outlier_std
self.max_stale_minutes = max_stale_minutes
self.min_gap_minutes = min_gap_minutes # Store as minutes
self.logger = logging.getLogger('DataQualityChecker')
# Define market hours in UTC (corrected times)
self.MARKET_OPEN_UTC = 14# 14:30 UTC = 9:30 AM ET
self.MARKET_OPEN_MIN = 30# Market opens at 14:30
self.MARKET_CLOSE_UTC = 21# 21:00 UTC = 4:00 PM ET
self.MARKET_CLOSE_MIN = 0 # Market closes at 21:00
defis_market_hours(self, dt: datetime) -> bool:
"""Check if a given datetime is within market hours"""
ifisinstance(dt, pd.Timestamp):
dt = dt.to_pydatetime()
# Check if it's a weekday (Monday = 0, Sunday = 6)
if dt.weekday() >= 5: # Saturday or Sunday
returnFalse
# Convert to UTC if needed
if dt.tzinfo isNone:
dt = dt.replace(tzinfo=pytz.UTC)
elif dt.tzinfo != pytz.UTC:
dt = dt.astimezone(pytz.UTC)
# Check if within market hours
if dt.hour == self.MARKET_OPEN_UTC:
return dt.minute >= self.MARKET_OPEN_MIN
elif dt.hour == self.MARKET_CLOSE_UTC:
return dt.minute < self.MARKET_CLOSE_MIN
else:
return self.MARKET_OPEN_UTC < dt.hour < self.MARKET_CLOSE_UTC
defis_same_trading_day(self, dt1: datetime, dt2: datetime) -> bool:
"""Check if two timestamps belong to the same trading day"""
ifisinstance(dt1, pd.Timestamp):
dt1 = dt1.to_pydatetime()
ifisinstance(dt2, pd.Timestamp):
dt2 = dt2.to_pydatetime()
return (dt1.date() == dt2.date() and
self.is_market_hours(dt1) and
self.is_market_hours(dt2))
defanalyze_gaps(self, df: pd.DataFrame) -> Tuple[Dict, timedelta]:
"""Analyze data gaps with detailed statistics and consistent metrics"""
try:
gap_info = {}
total_gap_duration = timedelta(0)
# Filter for market hours
market_hours_mask = df.index.map(self.is_market_hours)
df_market = df[market_hours_mask].copy()
# Calculate missing values per column for market hours only
missing_values = df_market.isnull().sum()
gap_info['missing_values'] = missing_values[missing_values >
0]
# Time gap analysis within market hours
time_diffs = df_market.index.to_series().diff()
min_gap = pd.Timedelta(minutes=self.min_gap_minutes) # Convert to Timedelta with minutes
# Filter gaps and handle trading day boundaries
market_gaps = {}
for time, gap in time_diffs[time_diffs > min_gap].items():
start_time = time - gap
# Only count gap if both times are in the same trading day
if self.is_same_trading_day(start_time, time):
market_gaps[time] = gap
gaps = pd.Series(market_gaps)
# Calculate total gap duration (market hours only)
ifnot gaps.empty:
total_gap_duration = pd.Timedelta(gaps.sum())
# Sort gaps by duration and get largest ones using sort_values and head instead of nlargest
sorted_gaps = gaps.sort_values(ascending=False)
gap_info['gap_count'] = len(gaps)
gap_info['first_few_gaps'] = gaps.head().to_dict()
gap_info['largest_gaps'] = sorted_gaps.head(5).to_dict()
# Calculate average sampling frequency for market hours
iflen(df_market) > 1:
trading_day_diffs = []
current_day = None
last_time = None
for idx in df_market.index:
if current_day != idx.date():
current_day = idx.date()
last_time = None
if last_time isnotNone:
diff = idx - last_time
if diff <= pd.Timedelta(minutes=5): # Only include reasonable gaps
trading_day_diffs.append(diff)
last_time = idx
if trading_day_diffs:
gap_info['avg_sampling_freq'] = pd.Timedelta(sum(trading_day_diffs, pd.Timedelta(0)) / len(trading_day_diffs))
else:
gap_info['avg_sampling_freq'] = pd.Timedelta(0)
else:
gap_info['avg_sampling_freq'] = pd.Timedelta(0)
# Data ranges for market hours only
ranges = {}
for col in df_market.columns:
if df_market[col].dtype in [np.float64, np.int64]:
ranges[col] = {
'min': df_market[col].min(),
'max': df_market[col].max()
}
gap_info['data_ranges'] = ranges
# Special spread statistics for market hours if available
if'spread'in df_market.columns:
gap_info['spread_stats'] = df_market['spread'].describe()
return gap_info, total_gap_duration
except Exception as e:
self.logger.error(f"Error in gap analysis: {e}")
raise
defcheck_data_quality(self, df: pd.DataFrame) -> DataQualityMetrics:
"""Perform comprehensive data quality checks"""
try:
# Filter for market hours
market_hours_mask = df.index.map(self.is_market_hours)
df_market = df[market_hours_mask]
# Skip quality check if no market hours data
iflen(df_market) == 0:
return DataQualityMetrics(
missing_data_pct=1.0,
outlier_pct=0.0,
stale_data_pct=0.0,
gaps_detected={},
gap_count=0,
gap_duration=timedelta(0),
data_freshness=timedelta.max,
quality_score=0.0
)
# Missing data analysis for market hours
missing_pct = df_market.isnull().mean()
# Outlier detection for market hours
outliers = {}
for col in df_market.select_dtypes(include=[np.number]).columns:
mean = df_market[col].mean()
std = df_market[col].std()
outliers[col] = df_market[col][abs(df_market[col] - mean) > self.max_outlier_std * std]
outlier_pct = sum(len(v) for v in outliers.values()) / len(df_market)
# Stale data detection for market hours only
stale_data = pd.Series(False, index=df_market.index)
last_update = None
current_day = None
for idx in df_market.index:
if current_day != idx.date():
current_day = idx.date()
last_update = None
if last_update isnotNone:
time_diff = idx - last_update
if time_diff > pd.Timedelta(minutes=self.max_stale_minutes):
stale_data[idx] = True
last_update = idx
stale_pct = stale_data.mean()
# Enhanced gap detection for market hours
gaps, total_gap_duration = self.analyze_gaps(df)
# Data freshness (use last market hours data point)
current_time = datetime.now(pytz.UTC)
if self.is_market_hours(current_time):
freshness = current_time - df_market.index[-1]
else:
# Find the last market close time
last_market_close = current_time.replace(
hour=self.MARKET_CLOSE_UTC,
minute=0,
second=0,
microsecond=0
)
ifnot self.is_market_hours(last_market_close):
last_market_close -= timedelta(days=1)
freshness = last_market_close - df_market.index[-1]
# Calculate overall quality score (0-1) with adjusted gap penalty
expected_samples = len(pd.date_range(
df_market.index[0],
df_market.index[-1],
freq='1min'
))
gap_ratio = gaps['gap_count'] / expected_samples
gap_penalty = min(0.5, gap_ratio) # Cap gap penalty at 0.5
quality_score = 1.0 - (
0.3 * missing_pct.mean() +
0.2 * outlier_pct +
0.2 * stale_pct +
0.3 * gap_penalty
)
return DataQualityMetrics(
missing_data_pct=missing_pct.mean(),
outlier_pct=outlier_pct,
stale_data_pct=stale_pct,
gaps_detected=gaps,
gap_count=gaps['gap_count'],
gap_duration=total_gap_duration,
data_freshness=freshness,
quality_score=quality_score
)
except Exception as e:
self.logger.error(f"Error in data quality check: {e}")
raise
其中DataMonitor类具有收集、处理和更新指标的核心功能。它连接到TimeScaleDb,检索数据并同时处理多个符号。最后,它打印有关差距分析、监控指标、统计数据和错误日志的详细信息。
class DataMonitor:
"""Data quality checks and monitoring"""
def__init__(self,
db_config: Dict[str, str],
cache_size: int = 100,
enable_monitoring: bool = False,
monitoring_port: int = 8080):
self.db_config = db_config
self.pool = None
self.logger = logging.getLogger('DataMonitor')
# Initialize components
self.quality_checker = DataQualityChecker()
self.cache_manager = CacheManager(cache_size=cache_size)
self.enable_monitoring = enable_monitoring
# Initialize metrics
self.current_metrics = {
'processing_metrics': {},
'quality_metrics': {},
'error_metrics': {}
}
asyncdefinitialize(self):
"""Initialize system components"""
try:
# Initialize database pool
self.pool = await asyncpg.create_pool(**self.db_config)
self.logger.info("Database connection pool initialized")
except Exception as e:
self.logger.error(f"Error initializing system: {e}")
raise
deflog_error(func):
"""Decorator for error logging and monitoring"""
@wraps(func)
asyncdefwrapper(self, *args, **kwargs):
try:
returnawait func(self, *args, **kwargs)
except Exception as e:
error_info = {
'error': str(e),
'traceback': traceback.format_exc(),
'timestamp': datetime.now(pytz.UTC).isoformat()
}
# Update error metrics
self.current_metrics['error_metrics'][func.__name__] = error_info
# Log error
self.logger.error(f"Error in {func.__name__}: {e}")
self.logger.error(traceback.format_exc())
raise
return wrapper
@log_error
asyncdefget_market_data(self,
symbol: str,
start_time: datetime,
end_time: datetime) -> pd.DataFrame:
"""Get market data with caching and quality checks"""
try:
# Check cache first
cache_key = self.cache_manager.get_cache_key(symbol, start_time, end_time)
cached_data = self.cache_manager.get_from_cache(cache_key)
if cached_data isnotNone:
return cached_data
# Fetch from database
asyncwith self.pool.acquire() as conn:
query = """
SELECT time, price, volume, bid, ask, vwap, spread,
trades_count, microstructure_imbalance
FROM market_data
WHERE symbol = $1
AND time >= $2
AND time < $3
ORDER BY time;
"""
records = await conn.fetch(query, symbol, start_time, end_time)
# Convert to DataFrame
df = pd.DataFrame(records, columns=[
'time', 'price', 'volume', 'bid', 'ask', 'vwap',
'spread', 'trades_count', 'microstructure_imbalance'
])
if df.empty:
self.logger.warning(f"No data found for {symbol}")
returnNone
# Set time as index and rename price to close
df.set_index('time', inplace=True)
df.rename(columns={'price': 'close'}, inplace=True)
# Check data quality
quality_metrics = self.quality_checker.check_data_quality(df)
# Print detailed gap analysis
print(f"\nAnalyzing data quality for {symbol}:")
print("\nMissing values per column:")
print(quality_metrics.gaps_detected['missing_values'])
print(f"\nFound {quality_metrics.gaps_detected['gap_count']} time gaps larger than 5 seconds:")
print("First few gaps:")
for time, gap in quality_metrics.gaps_detected['first_few_gaps'].items():
print(f"{time}: {gap}")
print("\nLargest gaps:")
for time, gap in quality_metrics.gaps_detected['largest_gaps'].items():
print(f"{time}: {gap}")
print(f"\nAverage sampling frequency: {quality_metrics.gaps_detected['avg_sampling_freq']}")
print("\nData ranges:")
for col, range_info in quality_metrics.gaps_detected['data_ranges'].items():
print(f"{col}: {range_info['min']:.2f} to {range_info['max']:.2f}")
if'spread_stats'in quality_metrics.gaps_detected:
print("\nSpread statistics:")
print(quality_metrics.gaps_detected['spread_stats'])
# Update monitoring metrics
self.current_metrics['quality_metrics'][symbol] = {
'quality_score': quality_metrics.quality_score,
'missing_data_pct': quality_metrics.missing_data_pct,
'data_freshness': quality_metrics.data_freshness.total_seconds(),
'gap_count': quality_metrics.gap_count,
'avg_sampling_freq': str(quality_metrics.gap_duration)
}
# Cache if quality is good
if quality_metrics.quality_score >= 0.8:
self.cache_manager.store_in_cache(cache_key, df)
return df
except Exception as e:
self.logger.error(f"Error fetching market data: {e}")
raise
@log_error
asyncdefprocess_symbol(self,
symbol: str,
start_time: datetime,
end_time: datetime) -> pd.DataFrame:
"""Process symbol with monitoring"""
start_processing = datetime.now()
try:
# Get market data
df = await self.get_market_data(symbol, start_time, end_time)
if df isNone:
returnNone
# Calculate processing metrics
end_processing = datetime.now()
processing_time = (end_processing - start_processing).total_seconds()
metrics = ProcessingMetrics(
processing_time=processing_time,
memory_usage=df.memory_usage().sum(),
error_count=0,
cache_hit_rate=self.cache_manager.hit_rate,
feature_count=len(df.columns)
)
# Update monitoring metrics
self.current_metrics['processing_metrics'][symbol] = {
'processing_time'
: float(metrics.processing_time),
'memory_usage': int(metrics.memory_usage),
'feature_count': int(metrics.feature_count),
'gap_analysis_time': float(processing_time),
'top_features': {},
'gap_metrics': {
'gap_count': len(df.index.to_series().diff()[df.index.to_series().diff() > pd.Timedelta(seconds=5)]),
'total_gap_duration': float(df.index.to_series().diff().sum().total_seconds())
}
}
return df
except Exception as e:
self.logger.error(f"Error processing symbol {symbol}: {e}")
self.current_metrics['error_metrics'][symbol] = {
'error': str(e),
'traceback': traceback.format_exc(),
'timestamp': datetime.now(pytz.UTC).isoformat()
}
raise
@log_error
asyncdefprocess_multiple_symbols(self,
symbols: List[str],
start_time: datetime,
end_time: datetime) -> Dict[str, pd.DataFrame]:
"""Process multiple symbols concurrently"""
try:
tasks = []
for symbol in symbols:
task = asyncio.create_task(
self.process_symbol(symbol, start_time, end_time)
)
tasks.append(task)
results = await asyncio.gather(*tasks, return_exceptions=True)
# Process results
processed_results = {}
for symbol, result inzip(symbols, results):
ifisinstance(result, Exception):
self.logger.error(f"Error processing {symbol}: {result}")
continue
if result isnotNone:
processed_results[symbol] = result
return processed_results
except Exception as e:
self.logger.error(f"Error in parallel processing: {e}")
raise
asyncdefcleanup(self):
"""Cleanup resources"""
if self.pool:
await self.pool.close()
self.logger.info("Database connection pool closed")
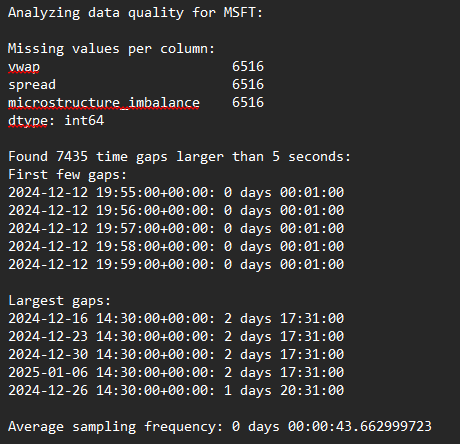
以下展示的是修改前的初始输出。可以观察到,在相近时间点出现了连续两天的数据间隔,同时存在6516个缺失值。实际上,这些情况属于正常现象,其根源在于代码中未纳入任何关于市场交易时间的实现逻辑。其中,65小时的时间间隔涵盖了周末闭市(周五闭市至周一开市)以及因圣诞节假期闭市导致的12月26日交易时段缩短。
在此详细阐述这些情况,是因为对于任何缺乏经验、处理原始数据的量化交易从业者而言,这类问题具有一定的普遍性。一旦对其有了深入理解并掌握相应处理方法,后续在面对类似情况时,便会将其视为常规操作,无需投入过多额外思考。
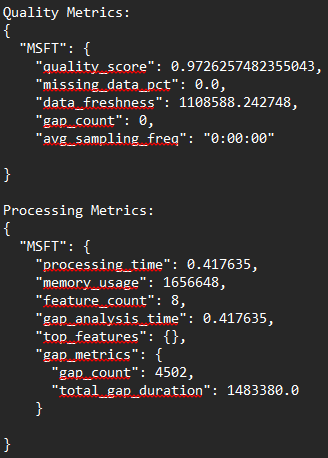
以下呈现的是初始运行的质量及处理指标。质量得分仅为65%,而缺失数据比例高达10%,这一数据偏差程度较为显著。可以注意到,此次初始运行涵盖了131个特征,同时还包含了部分特征相关的指标。而最终版本将仅以市场数据作为特征进行考量 。
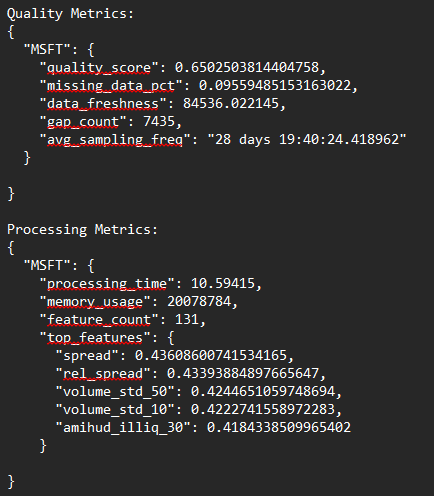
下面是数据的最终输出。这考虑了市场时间和市场收盘时1分钟的差距,这解决了整个差距问题。质量评分现在是%97,没有缺失的数据,没有差距。