本文主要探讨了如何合理运用大语言模型(LLMs)在实证研究中,同时考虑了其存在的局限性。通过构建一个计量经济学框架来解答这一问题,将实证任务划分为预测和估计两种类型。文章深入探讨了LLMs在实证研究中的应用潜力及其面临的挑战,并提出了相应的解决方案。
LLMs能够在许多实证应用中发挥重要作用,但在使用时必须注意其局限性,例如可能出现的训练泄漏、脆弱性等。通过合理运用,可以在保持研究严谨性的基础上,拓宽实证研究的边界。
在解决预测问题时,LLMs的有效使用需要满足“无训练泄漏”的条件。研究者应选择开源的LLM,这些模型清楚地记录了它们的训练数据,或者提供了明确的时间戳,以确保模型在测试集上表现良好。
在解决估计问题时,LLMs可以用来自动化现有的测量程序,降低数据收集成本。然而,这需要研究者收集基准数据来实证建模LLM可能出现的误差。在没有基准数据的情况下,使用LLM输出的研究者可能会面临一些挑战。
本文构建的计量经济学框架可以涵盖LLMs在研究中的一些新应用方式。例如,LLMs在生成假设时的用法与预测问题的结构相似,也需要满足“无训练泄漏”的条件。此外,LLM越来越多地被应用于模拟人类受试者的反应,在这种情况下,收集验证数据的重要性也得到了强调。
本文发展的计量经济学框架为在实证研究中运用LLM制定了一系列有意义的规则。只要遵循这些规则,就可以有效利用LLM在实证研究中提高效率和准确性。

邮件:econometrics666@126.com所有计量经济圈方法论丛的code程序, 宏微观数据库和各种软件都放在社群里.欢迎到计量经济圈社群交流访问.2025年,三位来自Chicago和MIT或Harvard的美国学者(两位印度裔)共同完成了一篇具有框架性的论文,题为“Large Language Models: An Applied Econometric Framework”。
这篇论文主要探讨了一个核心问题:大语言模型(LLM)能力很强大,但也有局限性,比如有时会给出不准确的答案等。那么,我们该如何在充分考虑其局限性的前提下,在实证研究中充分利用大语言模型(LLMs)的新能力呢?为了解答这一问题,论文构建了一个计量经济学框架,将实证任务划分为两种类型:预测和估计。Jens Ludwig, Sendhil Mullainathan & Ashesh Rambachan, 2025, Large Language Models: An Applied Econometric Framework, NBER.
本文深入探讨了如何在实证研究中运用大语言模型(LLMs)的新能力,以及如何在充分考虑其尚未完全被理解的局限性的前提下,合理地利用这些能力。为此,本文构建了一个计量经济学框架来解答这一问题,该框架将实证任务划分为两种类型。1.在处理预测问题,包括假设生成时,使用大语言模型(LLMs)是有效的,但需满足一个关键条件:LLM的训练数据集与研究者的样本之间不能出现“训练泄漏”(no leakage)。为确保这一点,应选择开源的LLM,这类模型的训练数据有详细的文档记录,并且其权重已经公开发布。2.当利用LLM的输出解决估计问题,即自动化某些经济概念的度量(无论是基于文本还是人类受试者)时,研究者至少需要收集一些验证数据。若缺少这些验证数据,就无法评估和修正LLM自动化过程中的误差。只要按照这些步骤操作,LLM的输出就能在实证研究中使用,并达到我们期望的计量经济学标准。这篇文章通过金融学和政治经济学的两个例子发现,这些要求是很严格的。要是不遵守这些要求,大语言模型(LLMs)的不足就会让实证估计的结果不准确。研究结果表明,大家对在实证研究中使用LLMs感到兴奋是有道理的:LLMs能够让研究者仅凭少量的语言数据就能进行预测和估计,但关键在于必须采取一些保障措施。
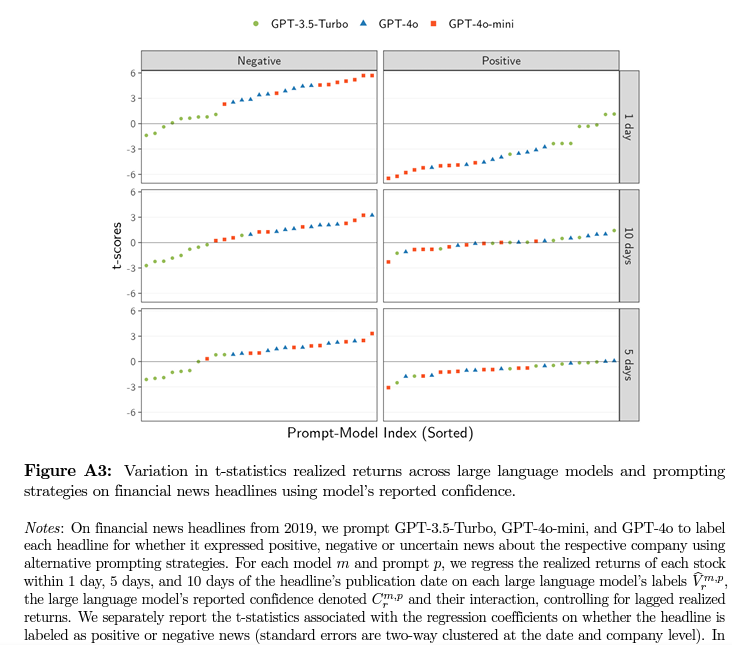
大语言模型(LLMs)既令人惊叹又让人困惑。一方面,它们能够出色地完成许多出人意料的任务;另一方面,它们偶尔也会犯一些意想不到的错误,而这些错误背后的原因尚未完全明了。本文旨在探讨如何在实证研究中充分挖掘LLMs的创新潜力,同时又不盲目地将其输出视为绝对准确无误的结论。本文的目标是分析如何在坚守实证研究严谨性的前提下,合理运用这些既强大又难以捉摸的工具,以充分发挥它们在研究中的积极作用,同时规避可能带来的风险和误导。我们可以将一个较为熟悉的算法——普通最小二乘法(OLS)应用于本文的研究。简言之,OLS是一种算法,当其应用于一组数据时,会计算出一个系数β,该系数能够使误差的平方和达到最小值。在计量经济学中,有明确的阐述,研究者需要对数据的来源,即数据生成过程(DGP)做出一系列假设,这样才能为算法得出的结果提供一个可靠的理论支撑。例如,若我们希望将系数β解释为条件期望函数的最佳线性无偏估计量(BLUE),那么高斯-马尔科夫定理便会明确指出,需要对数据生成过程(DGP)做出哪些假设,并且要为这些假设提供合理的解释。又如,若我们想将β视为因果效应,那么就必须为条件独立性假设(CIA)进行有力的辩护。从这个角度看,计量经济学就像是给实证研究者提供了一份契约:若想对估计结果赋予特定的解释,研究者就必须对相应的假设进行明确阐述和充分论证,而这些假设正是研究者必须认真对待和深入探讨的内容。合理运用大语言模型(LLMs)同样需要一份类似的“契约”。研究者必须明确的是,为了得出特定的推论,需要对LLMs的哪些具体假设进行辩护。然而,目前尚未存在这样一份契约,因为制定它面临着诸多困难。其中一部分难题在于,精准地建模LLMs的内部工作机制极具挑战性。LLMs是一系列多样且动态的、极为复杂的机器学习模型,包含多个交互层次以及数十亿个参数。此外,它们的训练数据集、架构(以及其他众多细节)通常被刻意隐藏(因为LLMs属于专有的商业产品)。除此之外,对LLMs的输出进行建模也困难重重。计算机科学家们一直在努力描述LLMs的脆弱性,这种脆弱性使得LLMs在某些任务中能够创造出令人惊叹的成果,但在其他任务中却可能出现荒谬的失误。本文构建了一个计量经济学框架,为大语言模型(LLMs)量身定制了一份相应的“契约”。即便这些模型极为复杂,且无需对其输出质量进行预先假设,该框架依然能够有效发挥作用。它着重关注研究者如何利用LLM处理文本并生成输出,这些输出可以与传统经济变量相联系并进行分析。鉴于这些算法的不透明性和多样性,本文将LLM从训练数据到生成特定文本响应的整个过程视作一个“黑箱”。在此基础上,该框架进一步区分了两种类型的实证应用,即预测和估计,并得出了四个主要结论。本文的第一个主要结论聚焦于预测问题,即研究者如何利用相关文本对某个经济变量进行预测。以资产定价为例,我们或许会思考如何借助新闻标题来预测股票价格。研究发现,若想让LLM的输出在预测问题中发挥有效作用,LLM需要满足一个关键条件——“无训练泄漏”。假设研究者对收集到的每一段文本都进行提示,以生成预测结果,并通过计算LLM在研究者数据集上的样本平均损失来评估其预测质量。研究表明,只有当LLM的训练数据集与研究者自己的数据集没有重叠时,LLM的样本平均损失才能真实地反映其样本外的预测性能。简言之,在这种工作流程里,研究者将LLM视作一种从文本到经济变量的预测工具,同时把自己收集的数据集当作测试样本。只有当LLM未曾对测试样本进行过训练时,这种使用方式才具有有效性。“无训练泄漏”这一条件在使用LLM时经常会被打破,因为这些模型的训练数据集庞大且神秘,通常被刻意隐藏。这在计算机科学领域是一个众所周知的难题,研究者们担心LLM可能已经在用来测试其表现的标准数据集上提前训练过了。本文通过金融学和政治经济学的两个例子,展示了在与经济学相关的情况下,“无训练泄漏”这一条件也被违反了。研究发现,GPT-4很可能已经在经济数据集上进行过训练,因为它似乎能够准确记住许多财经新闻标题和国会立法的文本。尽管“无训练泄漏”这一条件有时会被违反,但预测依然是一个很有潜力的应用场景。在许多实证应用中,通过合理选择LLM,可以可靠地保证“无训练泄漏”条件。具体地,研究者应选择开源的LLM,这类模型清楚地记录了它们的训练数据,或者提供了明确的时间戳,表明模型在某个时间点之后没有再更新,比如Llama系列模型和StoriesLM系列模型。选择这样的模型后,LLM在预测任务中可以发挥巨大的优势,特别是在利用文本进行预测时。通过文本预测经济变量,需要对语言的复杂结构和语义进行建模,这通常需要大量的训练数据。由于开源LLM已经在庞大的语料库上进行了预训练,学习了这些结构,它们可以作为基础,使得研究者即便在数据集较小的情况下,也能够进行准确的预测。本文的第二个主要结论涉及估计问题。也就是说,研究者希望将文本中所表达的某个经济概念,例如积极或消极的新闻、强硬的态度或政策主题,与下游的经济参数关联起来进行估计。举个例子,在研究党派性时,研究者想探究国会法案的政策主题与法案发起人的意识形态之间是否存在关联。本文假设研究者已经拥有一种耗费大量资源的程序,用于衡量这些经济概念,如果能够将该程序扩大应用,本文便认为是成功的。然而,这一过程可能既耗资又耗时,因此研究者希望借助LLM来自动化现有的测量程序,以一种较为经济的方式生成这些标签。但是,计算机科学领域的众多研究都记录了LLM在各种任务中的脆弱性。我们知道LLM的输出可能存在缺陷,那么该如何在估计问题中合理使用LLM的输出呢?本文借鉴了经济学中一个由来已久的理念,提出了一种实用的解决方案:先收集一小部分基准数据,然后利用这些数据来实际研究LLM的错误。这种方法在劳动经济学领域早已存在,在计量经济学中也得到了深入研究,近年来在机器学习领域也开始流行起来,例如Wang、McCormick和Leek(2020)、Angelopoulos等(2023)、Wei和Malik(2023)、Egami等(2024)以及Battaglia等(2024)等研究都在采用此法。本文以线性回归为例,阐释了基准数据的价值,将LLM的输出视为协变量或因变量。通过渐近论证,本文表明,利用基准样本来纠正LLM输出的偏差,不仅可以保持我们通常的计量经济学保证,一致性和渐近正态性,还能大幅降低衡量感兴趣经济概念的成本。本文还展示了,在基准数据的基础上,结合不够完美的LLM输出,能够在许多情况下提高最终估计的精度。这听起来可能有些出乎意料。在这里,LLM的作用类似于填补缺失值的工具。在经济学中,处理这种情况的常规方法是研究者使用自己的数据进行某种线性插补。那么,提高精度的额外信息来自哪里呢?答案是,LLM带来的新信息源于它在大规模外部语料库上的预训练。如果LLM在特定应用中足够准确,它就能增强研究者已经花费成本收集的验证数据的价值。本文通过使用国会立法数据进行蒙特卡洛模拟MCMC的有限样本实证,展示了这种性能提升。从这个角度看,估计问题也是LLM极具潜力的应用场景之一。只要研究者能够清晰地定义他们希望通过LLM自动化的测量流程,并收集基准数据来实证建模LLM可能出现的误差,就能实现这一目标。实际上,这不过是现有做法的小幅改进,因为在许多涉及LLM的实证应用中,研究者通常已经收集了此类基准数据。通过合理运用这一保障措施,LLM能够为研究者带来诸多益处:在降低数据收集成本的同时,某些情况下还能提高统计精度,并且保持我们在估计问题中所需的计量经济学保障。需要注意的是,这种在估计问题中有效利用LLM的方法,要求研究者使用现有的测量程序来收集基准数据。那么,如果无法收集到这些基准数据该怎么办呢?本文的第三个主要结论表明,在没有基准数据的情况下,使用LLM输出的插件估计能够恢复研究者的目标估计,但前提是LLM的输出必须准确无误。换言之,LLM必须能够精准地再现感兴趣的经济概念。因此,在没有基准数据的情况下,使用LLM输出的研究者可以直接主张LLM输出没有错误。也就是说,在前面的例子中,可以主张所选择的LLM和提示工程(prompt)策略正确地标记了所有国会法案的政策主题。然而,在计算机科学领域,即便是对LLM在基准任务上进行最宽松的性能测试,也未曾发现其能完美无缺地表现。而且,计算机科学研究还发现LLM十分脆弱:任务的微小改动,比如换了不同的LLM或者改变了提示,就会使LLM的表现大相径庭。本文提供了新的实证结果,展示了这种脆弱性对经济参数下游估计的影响。在本文对金融和政治经济学的应用研究中,结果表明,LLM输出在不同模型和提示之间的变化,会导致回归系数的大小、统计显著性,甚至符号发生重大变化。既然目前很难断定LLM的输出完全没有错误,那么在没有基准数据的情况下,使用LLM输出的研究者便面临两个选择。首先,研究者可能会尝试构建一个关于LLM误差的统计模型,就像本文在计量经济学的测量误差文献中所做的那样。虽然这一方法在理论上听起来不错,但将其应用于LLM似乎有些过于乐观。这就好比我们声称能够精准地建模一个连我们自己都不甚了解的算法的输出,以及我们无法直接观察到的事物之间的关系。其次,研究者可以宣称没有现有的测量流程需要自动化;相反,LLM的输出本身就是研究者所关注的量,而不是其他事物的替代品。虽然从理论假设上讲这是成立的,但很难想象有什么实际应用能让研究者真正感到满意。例如,当GPT-5推出时,研究者会愿意重新审查所有用GPT-4完成并已发表的研究成果吗?如果没有基准数据,这两种选择在实际应用中似乎都难以奏效。然而,如果能够收集到基准数据,本文的研究成果表明,LLM已经是一个非常强大的工具,可用于自动化现有的测量方法。尤其是在处理海量文本数据时,这种方法能够有效解决在扩大测量规模时成本过高的问题。本文的最后一个主要结论是证明了这个框架的通用性,它能够涵盖一些LLM在研究中的新应用方式。例如,本文认为LLM在生成假设时的用法与预测问题的结构颇为相似。这就意味着,本文的框架可以清晰地指出,在这种情况下有效使用LLM所需满足的条件——即“无训练泄漏”。另一个例子是,LLM越来越多地被应用于模拟人类受试者的反应,比如在调查或实验室实验中就有这样的应用。本文认为,这一任务的结构与估计问题相似,因此也强调了收集验证数据的重要性。具体地,需要进行实验、收集调查数据,至少要从一些真实的受试者那里获取数据,以确保LLM模拟的准确性和可靠性。这些结论并未要求必须详细阐述LLM是如何从训练数据生成输出的。起初,将这种新型AI工具视为黑箱,可能会让人感到不太满意,甚至有些不安。过去,计量经济学所设计的实证工具都有一套非常清晰的规则。然而如今,经济学家在新AI模型的使用方面扮演着越来越关键的角色,但我们对这些模型的构建过程却了解甚少。对于使用者而言,这常常会引发沮丧和困惑,因为在这个领域里,有人极力推崇,也有人心存疑虑。其实双方的观点都有其合理之处。AI工具确实能够在实证研究中大显身手,但前提是必须将其纳入一个计量经济学的框架之内,这个框架既不能提出不切实际的假设,也不能有所偏颇。本文就提供了一个这样的框架,为在实证研究中运用LLM制定了一系列有意义的规则。只要遵循这些规则,本文的研究结果表明,LLM能够在保持研究严谨性的基础上,拓宽实证研究的边界。How can we use the novel capacities of large language models (LLMs) in empirical research? And how can we do so while accounting for their limitations, which are themselves only poorly understood? We develop an econometric framework to answer this question that distinguishes between two types of empirical tasks. Using LLMs for prediction problems (including hypothesis generation) is valid under one condition: no ``leakage'' between the LLM's training dataset and the researcher's sample. No leakage can be ensured by using open-source LLMs with documented training data and published weights. Using LLM outputs for estimation problems to automate the measurement of some economic concept (expressed either by some text or from human subjects) requires the researcher to collect at least some validation data: without such data, the errors of the LLM's automation cannot be assessed and accounted for. As long as these steps are taken, LLM outputs can be used in empirical research with the familiar econometric guarantees we desire. Using two illustrative applications to finance and political economy, we find that these requirements are stringent; when they are violated, the limitations of LLMs now result in unreliable empirical estimates. Our results suggest the excitement around the empirical uses of LLMs is warranted -- they allow researchers to effectively use even small amounts of language data for both prediction and estimation -- but only with these safeguards in place.

关于机器学习,参看:1.机器学习之KNN分类算法介绍: Stata和R同步实现(附数据和代码),2.机器学习对经济学研究的影响研究进展综述,3.回顾与展望经济学研究中的机器学习,4.最新: 运用机器学习和合成控制法研究武汉封城对空气污染和健康的影响! 5.Top, 机器学习是一种应用的计量经济学方法, 不懂将来面临淘汰危险!6.Top前沿: 农业和应用经济学中的机器学习, 其与计量经济学的比较, 不读不懂你就out了!7.前沿: 机器学习在金融和能源经济领域的应用分类总结,8.机器学习方法出现在AER, JPE, QJE等顶刊上了!9.机器学习第一书, 数据挖掘, 推理和预测,10.从线性回归到机器学习, 一张图帮你文献综述,11.11种与机器学习相关的多元变量分析方法汇总,12.机器学习和大数据计量经济学, 你必须阅读一下这篇,13.机器学习与Econometrics的书籍推荐, 值得拥有的经典,14.机器学习在微观计量的应用最新趋势: 大数据和因果推断,15.R语言函数最全总结, 机器学习从这里出发,16.机器学习在微观计量的应用最新趋势: 回归模型,17.机器学习对计量经济学的影响, AEA年会独家报道,18.回归、分类与聚类:三大方向剖解机器学习算法的优缺点(附Python和R实现),19.关于机器学习的领悟与反思,20.机器学习,可异于数理统计,21.前沿: 比特币, 多少罪恶假汝之手? 机器学习测算加密货币资助的非法活动金额! 22.利用机器学习进行实证资产定价, 金融投资的前沿科学技术! 23.全面比较和概述运用机器学习模型进行时间序列预测的方法优劣!24.用合成控制法, 机器学习和面板数据模型开展政策评估的论文!25.更精确的因果效应识别: 基于机器学习的视角,26.一本最新因果推断书籍, 包括了机器学习因果推断方法, 学习主流和前沿方法,27.如何用机器学习在中国股市赚钱呢? 顶刊文章告诉你方法!28.机器学习和经济学, 技术革命正在改变经济社会和学术研究,29.世界计量经济学院士新作“大数据和机器学习对计量建模与统计推断的挑战与机遇”,30.机器学习已经与政策评估方法, 例如事件研究法结合起来识别政策因果效应了!31.重磅! 汉森教授又修订了风靡世界的“计量经济学”教材, 为博士生们增加了DID, RDD, 机器学习等全新内容!32.几张有趣的图片, 各种类型的经济学, 机器学习, 科学论文像什么样子?33.机器学习已经用于微观数据调查和构建指标了, 比较前沿!34.两诺奖得主谈计量经济学发展进化, 机器学习的影响, 如何合作推动新想法!35.前沿, 双重机器学习方法DML用于因果推断, 实现它的code是什么?
下面这些短链接文章属于合集,可以收藏起来阅读,不然以后都找不到了。
8年,计量经济圈近2500篇不重类计量文章,
可直接在公众号菜单栏搜索任何计量相关问题,
Econometrics Circle
计量经济圈组织了一个计量社群,有如下特征:热情互助最多、前沿趋势最多、社科资料最多、社科数据最多、科研牛人最多、海外名校最多。因此,建议积极进取和有强烈研习激情的中青年学者到社群交流探讨,始终坚信优秀是通过感染优秀而互相成就彼此的。




