DeepSeek最新论文《Inference-Time Scaling for Generalist Reward Modeling》为人工智能领域带来新突破。该研究探索了通用奖励模型的推理时间扩展,通过增加推理计算量提升模型性能。DeepSeek提出的DeepSeek-GRM模型结合创新训练方法和推理策略为领域提供新思路。论文展示了该模型在多个测试中的优越性,尤其是在需要复杂推理的任务上表现突出。外界猜测DeepSeek可能正在为下一代模型R2铺路。
DeepSeek发表的论文展示了在通用奖励模型的推理时间扩展方面的新思路和研究成果,为人工智能领域的发展带来突破。
论文提出了DeepSeek-GRM模型,结合创新的训练方法和推理策略,能够灵活应对各种任务,提高模型性能。实验结果显示,该模型在多个测试中击败了传统方法,尤其是在需要复杂推理的任务上表现抢眼。
DeepSeek-GRM模型的推广和应用可能会改变游戏规则,降低AI的训练成本,并通过推理阶段的优化实现突破。此外,该模型可能为DeepSeek的下一代模型R2的发布奠定基础,引发业界期待。
4月4日讯,人工智能领域的竞争从未停歇,而中国 AI 明星企业 DeepSeek 最新发布的论文《Inference-Time Scaling for Generalist Reward Modeling》(通用奖励模型的推理时间扩展)无疑为这场角逐再添一把火。这篇论文不仅展示了一种通过增加推理计算量提升模型性能的新思路,还让人不禁猜测:备受期待的 DeepSeek R2 模型可能已近在咫尺。大型语言模型的训练通常依赖海量数据和高昂算力,而在训练过程中奖励模型扮演着至关重要的角色,它为强化学习提供反馈信号,帮助模型优化输出。然而,传统的奖励模型通常针对特定领域(如数学问题或规则明确的游戏)设计,难以适应多样化的通用查询。此外,随着推理任务复杂性的增加,如何在推理阶段有效利用计算资源(即推理时间扩展,Inference-Time Scaling)成为一个亟待解决的问题。
OpenAI 的 o1 系列模型率先展示了推理时间扩展的潜力,通过延长推理过程中的“思维链”(Chain-of-Thought, CoT),显著提升了数学、编码等任务的性能。然而,如何将这一思路推广到通用奖励建模,并设计出高效、可扩展的解决方案,仍是研究领域的空白。
DeepSeek 的这篇论文正是在此背景下应运而生。研究团队的目标是探索“通用奖励模型的推理时间扩展”,即如何通过增加推理计算量提升奖励模型在各种任务中的表现,同时避免传统方法在训练资源上的过度依赖。论文提出了一种名为 DeepSeek-GRM 的模型,并结合创新的训练方法和推理策略,为这一领域提供了新的思路。
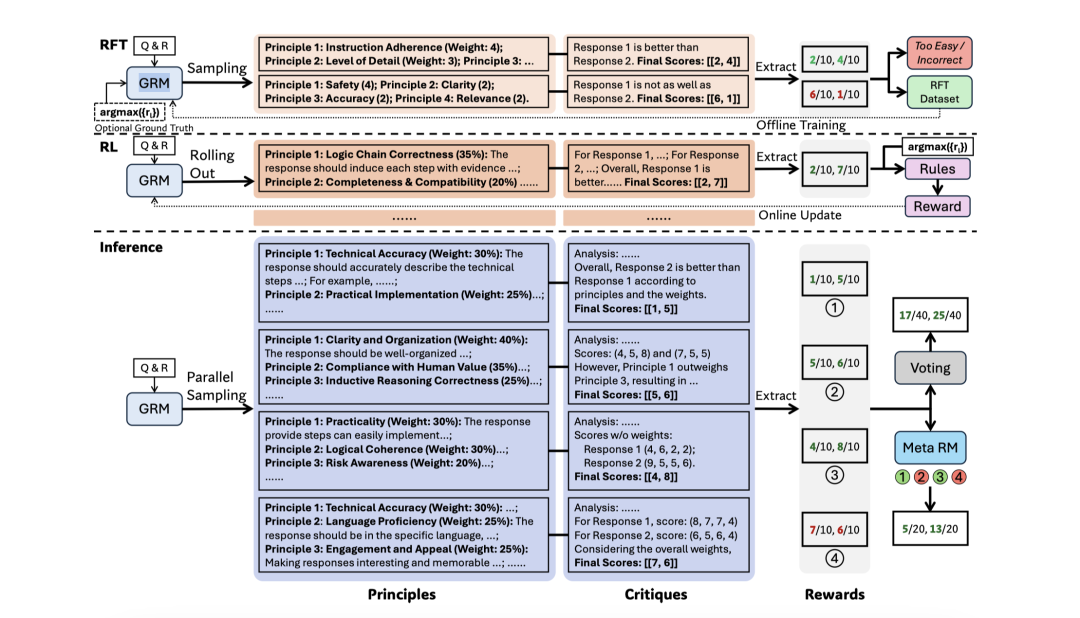
图3:SPCT的示意图,包括拒绝性微调、基于规则的强化学习以及推理过程中相应的可扩展行为。通过简单投票或元RM引导投票,利用大规模生成的原则实现推理时的扩展,从而在扩展的价值空间内产生更细粒度的结果奖励。
论文中,DeepSeek 推出了名为 DeepSeek-GRM 的新模型,搭配一种创新的训练方法“自原则批评调优”(SPCT)。这套组合拳让模型能在推理时动态调整输出,确保对各种复杂问题的回答更精准、更可靠。更令人兴奋的是,团队还设计了一个“元奖励模型”来协调多个候选答案,确保质量随着计算量的增加而稳步提升。
图1:在所有测试的RM基准上,使用不同RM进行推理时的性能扩展。结果展示了每种方法最多8个样本的情况,并且我们的结果进一步扩展到了32个样本。非斜体字体表示基于Gemma-2-27B的模型。
DeepSeek-GRM 的成功并非偶然,而是建立在一套巧妙的技术组合之上。核心在于它跳出了传统奖励模型的窠臼,采用了生成式评分方式(GRM),让模型能灵活应对各种任务,而非简单地比较优劣。与此同时,“自原则批评调优”(SPCT)让模型学会自我反省,通过强化学习不断优化判断,减少对人工干预的依赖。
推理时,DeepSeek-GRM 还能并行生成多个答案,再由“元奖励模型”从中挑出最佳方案,这种多线程操作让性能随着计算资源增加而显著提升。受 OpenAI o1 的启发,模型还融入了动态调整的“思维链”,根据问题难度灵活分配思考时间。这些创新共同打造了一个既聪明又高效的系统,展现了推理时间扩展的巨大潜力。
实验结果显示,DeepSeek-GRM 在多个测试中击败了传统方法,尤其是在需要复杂推理的任务上表现抢眼。比如,与那些只靠训练阶段堆砌资源的模型相比,DeepSeek-GRM 在相同预算下往往能交出更优的答卷。更重要的是,这种方法的扩展性极强——只要多给它一点“思考时间”,性能就能持续攀升。
表2:不同方法和模型在RM基准上的综合结果。下划线数字表示最佳性能,粗体数字表示在基准方法和我们的方法中的最佳性能,斜体字体表示标量或半标量RM。对于元RM引导投票(MetaRM),k_meta = 1/2 * k。
这一发现可能会改变游戏规则,它意味着未来的 AI 不一定需要无底洞般的训练成本,而是可以通过推理阶段的优化实现突破。
DeepSeek 的这篇论文来得正是时候。去年,其 R1 模型以开源姿态震撼业界,迅速成为开发者社区的宠儿。而随着推理时间扩展技术的亮相,外界普遍猜测,DeepSeek 可能正在为下一代模型——传闻中的 R2——铺路。如果 R2 真的整合了这种技术,它或许能进一步以更低的训练成本挑战 OpenAI 的 o1 系列,甚至在某些任务上实现“以小博大”的逆袭。
DeepSeek 的节奏非常快,从 R1 到现在的论文,他们显然在加速迭代。R2 如果能把推理时间扩展做到极致,可能会重新定义性价比的标杆。
与以往一样,DeepSeek 再次承诺将 DeepSeek-GRM 开源。这一举动不仅延续了其“技术普惠”的品牌形象,也为全球开发者提供了一个低门槛的实验平台。不过,论文也坦言,这项技术并非完美无缺——在处理极端复杂问题时,模型仍有改进空间。
尽管 DeepSeek 尚未正式公布 R2 的发布时间表,但这篇论文无疑点燃了业界的期待。AI 竞赛的下一幕,或许就藏在这套“多想几步”的技术背后。正如一些国外媒体所言:“DeepSeek 正在用行动证明,中国 AI 不只是追赶者,更是规则的改写者。”
无论 R2 是否即将来袭,DeepSeek 的最新突破已经足够引人注目。在这个技术日新月异的时代,他们的故事,才刚刚开始。
© AI范儿
要进“交流群”,请关注公众号获取进群方式
投稿、需求合作或报道请添加公众号获取联系方式

